This article is based on a talk I gave at mdevcon 2014. The talk also included a specific example to demonstrate the approach, but was otherwise a presentation of the following argument.
You probably read this blog because you write apps. Which is kind of cool, because I have been known to use apps. I’d be interested to hear what yours is about.
Not so fast! Let me make this clear first: I only buy page-based apps, they must use Core Data, and I automatically give one star to any app that uses storyboards.
OK, that didn’t sound like it made any sense. Nobody actually chooses which apps to buy based on what technologies or frameworks are used, they choose which apps to buy based on what problems those apps solve. On the experience they derive from using the software.
When we build our apps, the problem we’re solving and the experience we’re providing needs to be at the uppermost of our thoughts. You’re probably already used to doing this in designing an application: Apple’s Human Interface Guidelines describe the creation of an App Definition Statement to guide thinking about what goes into an app and how people will use it:
An app definition statement is a concise, concrete declaration of an app’s main purpose and its intended audience.
Create an app definition statement early in your development effort to help you turn an idea and a list of features into a coherent product that people want to own. Throughout development, use the definition statement to decide if potential features and behaviors make sense.
My suggestion is that you should use this idea to guide your app’s architecture and your class design too. Start from the problem, then work through solving that problem to building your application. I have two reasons: the first will help you, and the second will help me to help you.
The first reason is to promote a decoupling between the problem you’re trying to solve, the design you present for interacting with that solution, and the technologies you choose to implement the solution and its design. Your problem is not “I need a Master-Detail application”, which means that your solution may not be that. In fact, your problem is not that, and it may not make sense to present it that way. Or if it does now, it might not next week.
You see, designers are fickle beasts, and for all their feel-good bloviation about psychology and user experience, most are actually just operating on a combination of trend and whimsy. Last week’s refresh button is this week’s pull gesture is next week’s interaction-free event. Yesterday’s tab bar is today’s hamburger menu is tomorrow’s swipe-in drawer. Last decade’s mouse is this decade’s finger is next decade’s eye motion. Unless your problem is Corinthian leather, that’ll be gone soon. Whatever you’re doing for iOS 7 will change for iOS 8.
So it’s best to decouple your solution from your design, and the easiest way to do that is to solve the problem first and then design a presentation for it. Think about it. If you try to design a train timetable, then you’ll end up with a timetable that happens to contain train details. If you try to solve the problem “how do I know at what time to be on which platform to catch the train to London?”, then you might end up with a timetable, but you might not. And however the design of the solution changes, the problem itself will not: just as the problem of knowing where to catch a train has not changed in over a century.
The same problem that affects design-driven development also affects technology-driven development. This month you want to use Core Data. Then next month, you wish you hadn’t. The following month, you kind of want to again, then later you realise you needed a document database after all and go down that route. Solve the problem without depending on particular libraries, then changing libraries is no big deal, and neither is changing how you deal with those libraries.
It’s starting with the technology that leads to Massive View Controller. If you start by knowing that you need to glue some data to some view via a View Controller, then that’s what you end up with.
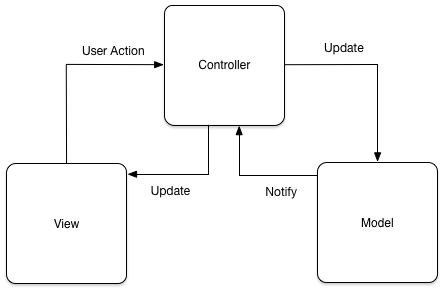
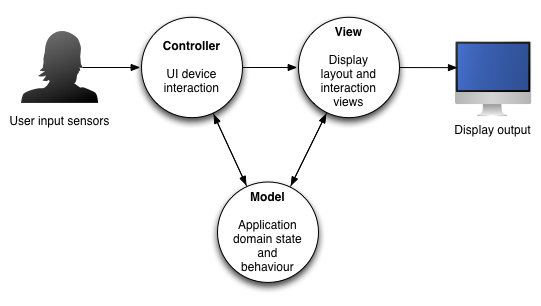
This problem is exacerbated, I believe, by a religious adherence to Model-View-Controller. My job here is not to destroy MVC, I am neither an iconoclast nor a sacrificer of sacred cattle. But when you get overly attached to MVC, then you look at every class you create and ask the question “is this a model, a view, or a controller?”. Because this question makes no sense, the answer doesn’t either: anything that isn’t evidently data or evidently graphics gets put into the amorphous “controller” collection, which eventually sucks your entire codebase into its innards like a black hole collapsing under its own weight.
Let’s stick with this “everything is MVC” difficulty for another paragraph, and possibly a bulleted list thereafter. Here are some helpful answers to the “which layer does this go in” questions:
- does my Core Data stack belong in the model, the view, or the controller? No. Core Data is a persistence service, which your app can call on to save or retrieve data. Often the data will come from the model, but saving and retrieving that data is not itself part of your model.
- does my networking code belong in the model, the view, or the controller? No. Networking is a communications service, which your app can call on to send or retrieve data. Often the data will come from the model, but sending and retrieving that data is not itself part of your model.
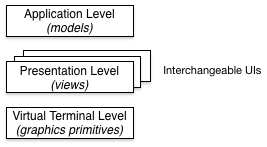
- is Core Graphics part of the model, the view, or the controller? No. Core Graphics is a display primitive that helps objects represent themselves on the display. Often those objects will be views, but the means by which they represent themselves are part of an external service.
So building an app in a solution-first approach can help focus on what the app does, removing any unfortunate coupling between that and what the app looks like or what the app uses. That’s the bit that helps you. Now, about the other reason for doing this, the reason that makes it easier for me to help you.
When I come to look at your code, and this happens fairly often, I need to work out quickly what it does and what it should do, so that I can work out why there’s a difference between those two things and what I need to do about it. If your app is organised in such a way that I can see how each class contributes to the problem being solved, then I can readily tell where I go for everything I need. If, on the other hand, your project looks like this:

Then the only thing I can tell is that your app is entirely interchangeable with every other app that claims to be nothing more than MVC. This includes every Rails app, ever. Here’s the thing. I know what MVC is, and how it works. I know what UIKit is, and why Apple thinks everything is a view controller. I get those things, your app doesn’t need to tell me those things again. It needs to reflect not the similarities, which I’ve seen every time I’ve launched Project Builder since around 2000, but the differences, which are the things that make your app special.
OK, so that’s the theory. We should start from the problem, and move to the solution, then adapt the solution onto the presentation and other technology we need to use to get a product we can sell this week. When the technologies and the presentations change, we can adapt onto those new things, to get the product we can sell next week, without having to worry about whether we broke solving the problem. But what’s the practice? How do we do that?
Start with the model.
Remember that, in Apple’s words:
model objects represent knowledge and expertise related to a specific problem domain
so solving the problem first means modelling the problem first. Now you can do this without regard to any particular libraries or technology, although it helps to pick a programming language so that you can actually write something down. In fact, you can start here:

A Foundation command-line tool has everything you need to solve your problem (in fact it contains a few more things than that, to make up for erstwhile deficiencies in the link editor, but we’ll ignore those things). It lets you make objects, and it lets you use all those boring things that were solved by computer scientists back in the 1760s like strings, collections and memory allocation.
So with a combination of the subset of Objective-C, the bits of Foundation that should really be in Foundation, and unit tests to drive the design of the solution, we can solve whatever problem it is that the app needs to solve. There’s just one difficulty, and that is that the problem is only solved for people who know how to send messages to objects. Now we can worry about those fast-moving targets of presentation and technology choice, knowing that the core of our app is a stable, well-tested collection of objects that solve our customers’ problem. We expose aspects of the solution by adapting them onto our choice of user interface, and similarly any other technology dependencies we need to introduce are held at arm’s length. We test that we integrate with them correctly, but not that using them ends up solving the problem.
If something must go, then we drop it, without worrying whether we’ve broken our ability to solve the problem. The libraries and frameworks are just services that we can switch between as we see fit. They help us solve our problem, which is to help everyone else to solve their problem.
And yes, when you come to build the user interface, then model-view-controller will be important. But only in adapting the solution onto the user interface, not as a strategy for stuffing an infinite number of coats onto three coat hooks.
References
None of the above is new, it’s just how Object-Oriented Programming is supposed to work. In the first part of my MVC series, I investigated Thing-Model-View-Editor and the progress from the “Thing” (a problem in the real world that must be solved) to a “Model” (a representation of that problem and its solution in the computer). That article relied on sources from Trygve Reenskaug, who described (in 1979) the process by which he moved from a Thing to a Model and then to a user interface.
In his 1992 book Object-Oriented Software Engineering: A Use-Case Driven Approach, Ivar Jacobson describes a formalised version of the same motion, based on documented use cases. Some teams replaced use cases with user stories, which look a lot like Reenskaug’s user goals:
An example: To get better control over my finances, I would need to set up a budget; to keep account
of all income and expenditure; and to keep a running comparison between budget and accounts.
Alastair Cockburn described the Ports and Adapters Architecture (earlier known as the hexagonal architecture) in which the application’s use cases (i.e. the ways in which it solves problems) are at the core, and everything else is kept at a distance through adapters which can easily be replaced.